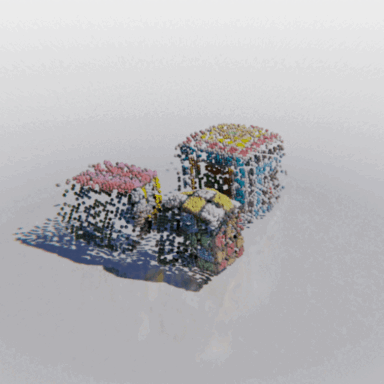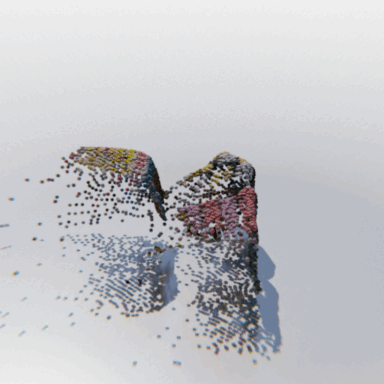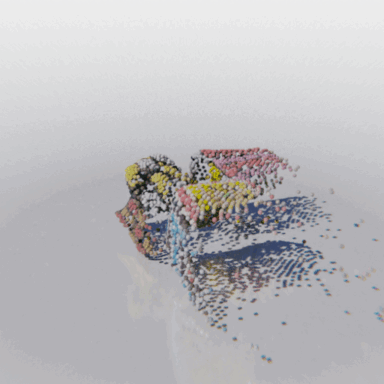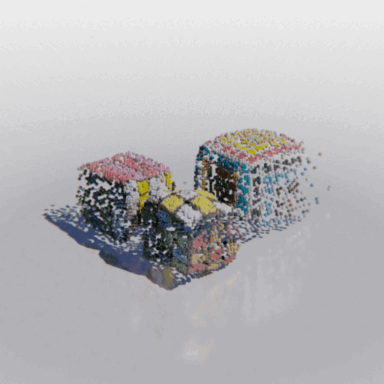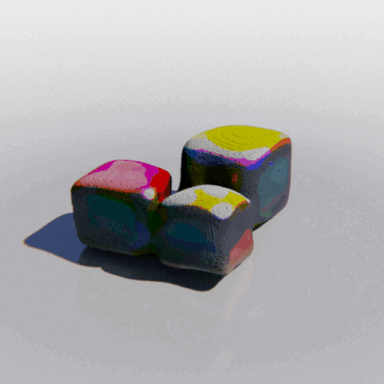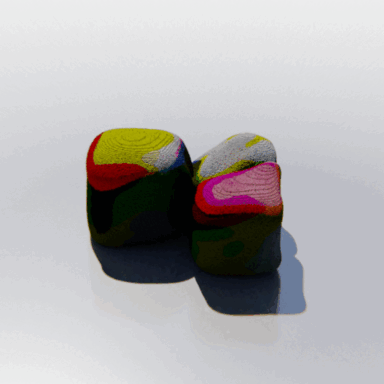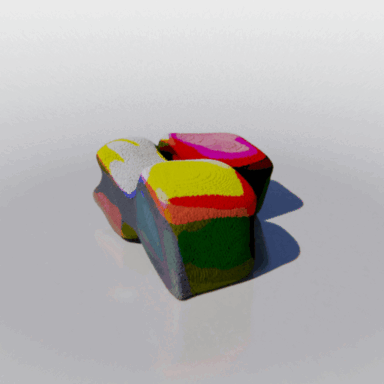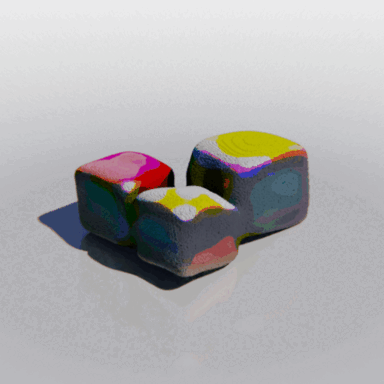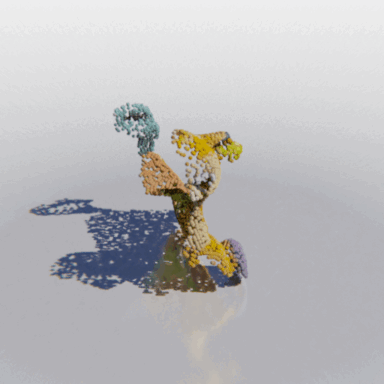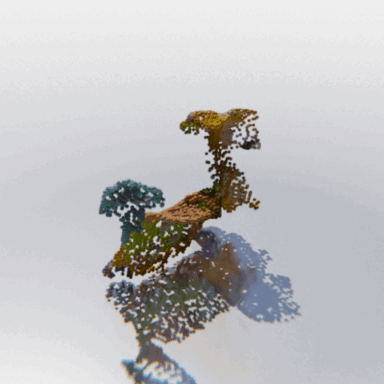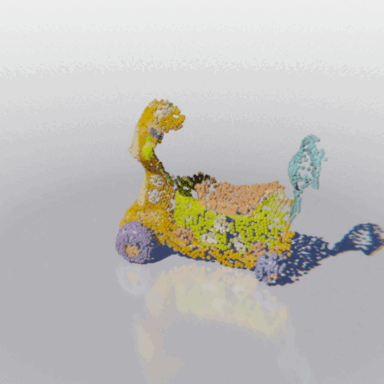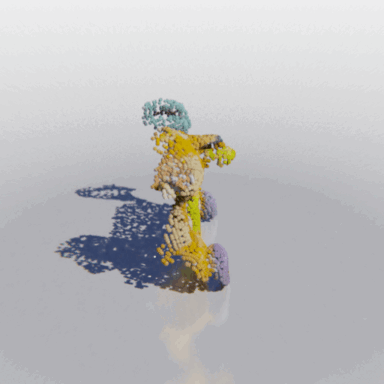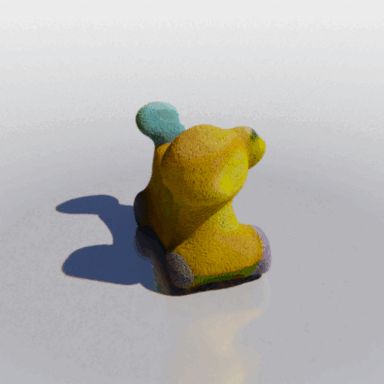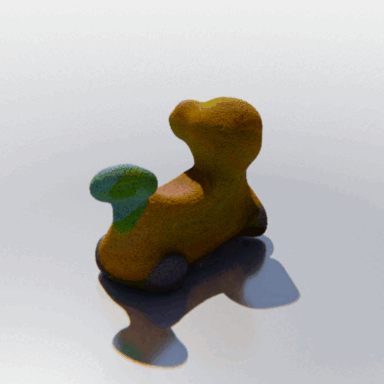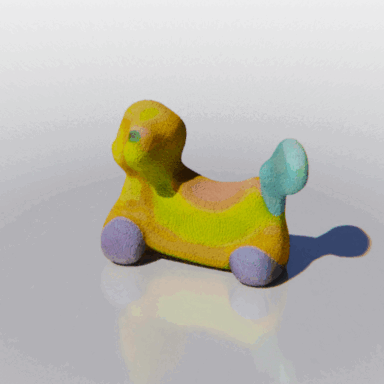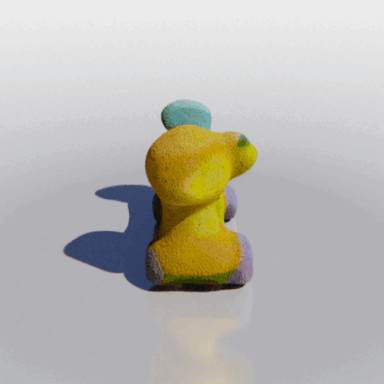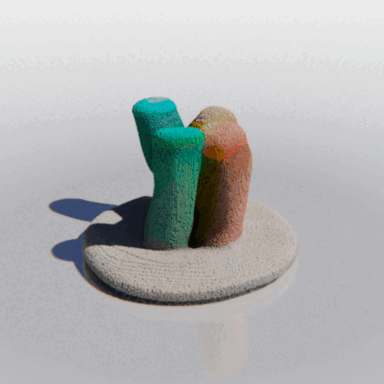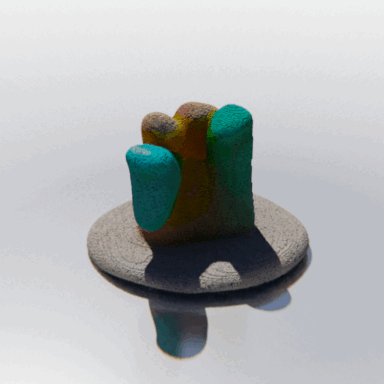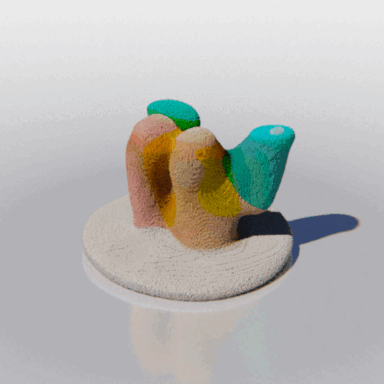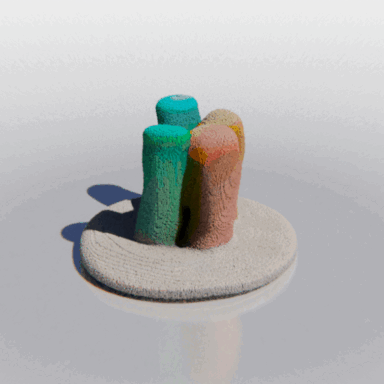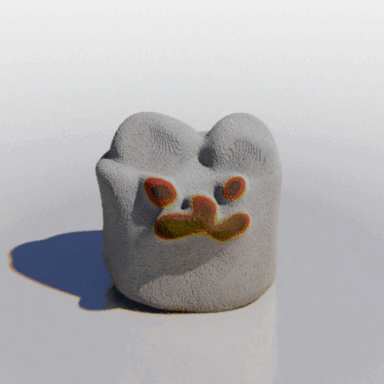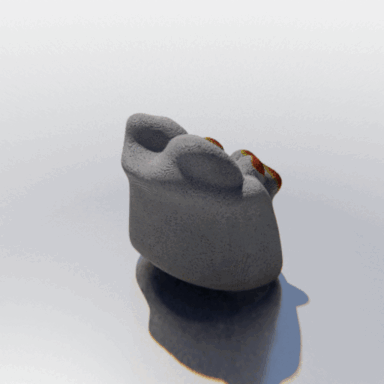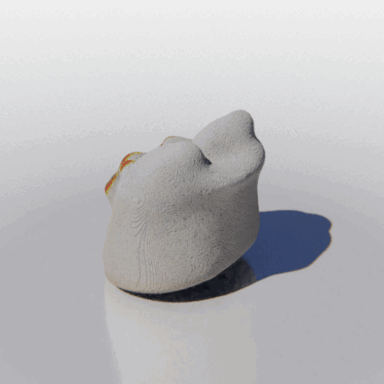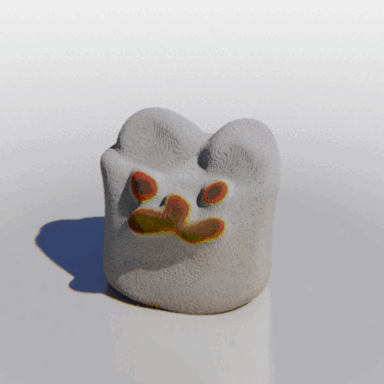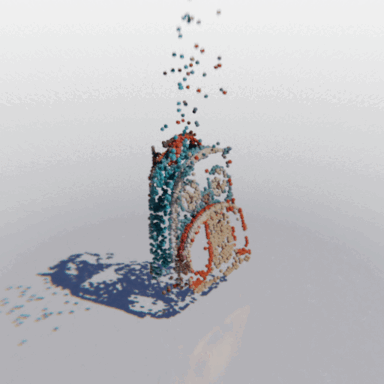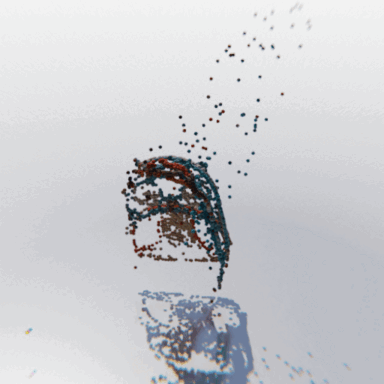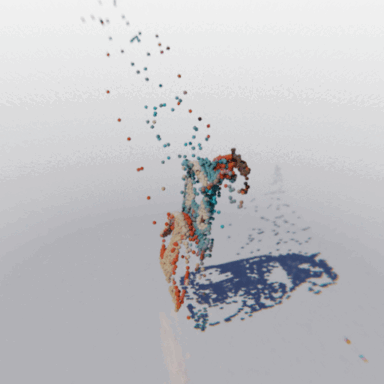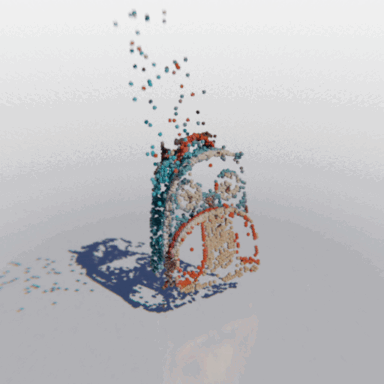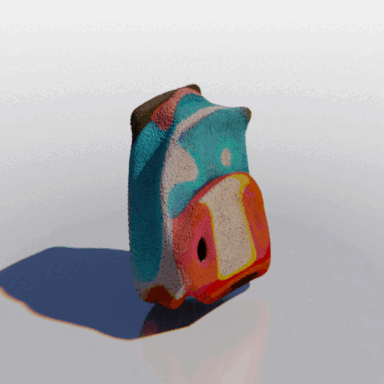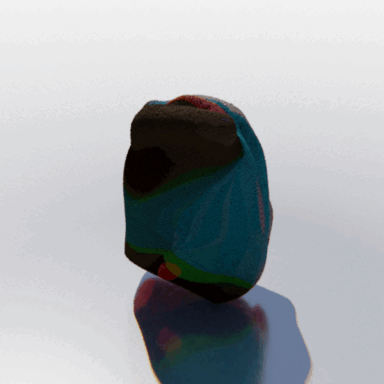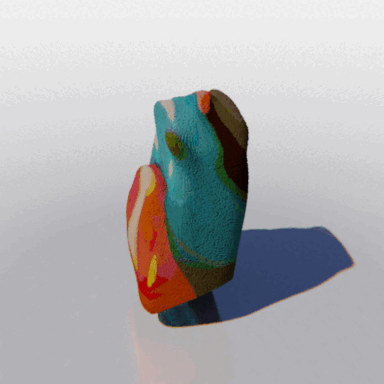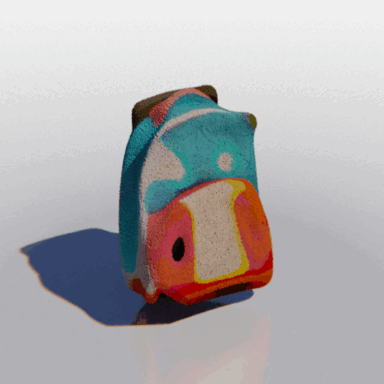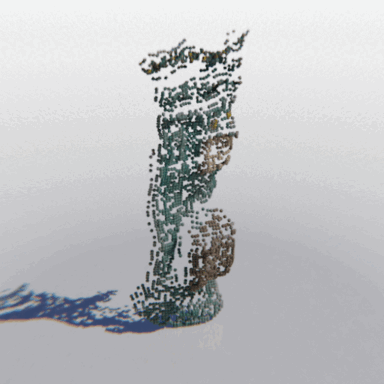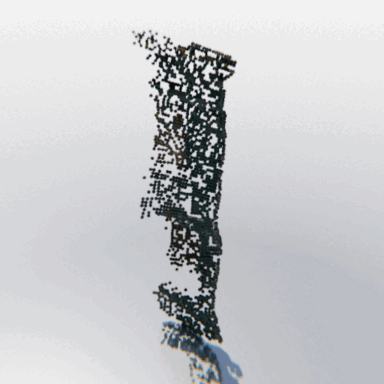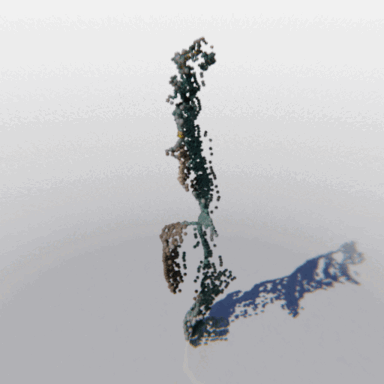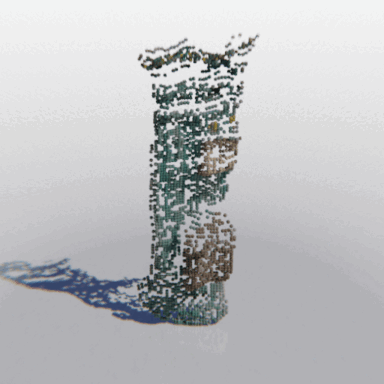Approach
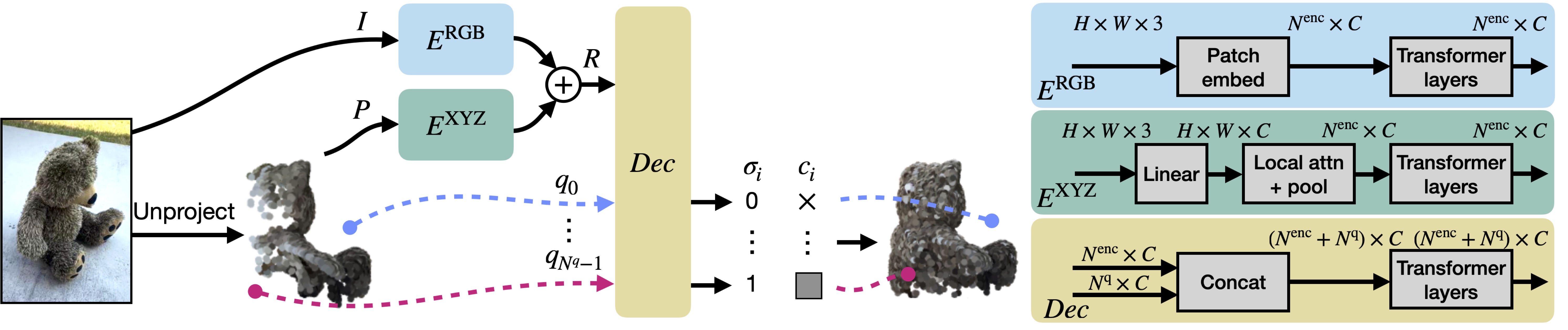
MCC adopts a simple encoder-decoder architecture. The input RGB-D image is fed to the encoder to produce an input encoding. The decoder inputs a query 3D point, along with the input encoding, to predict its occupancy probability and RGB color. This is illustrated in the figure below. MCC requires only points for supervision. This means that we can learn from large RGB-D datasets. The input channel D is read from depth sensors, as in iPhones, or computed by off-the-shelf depth models, e.g. MiDas, or computed by COLMAP in the case of multiview video streams.